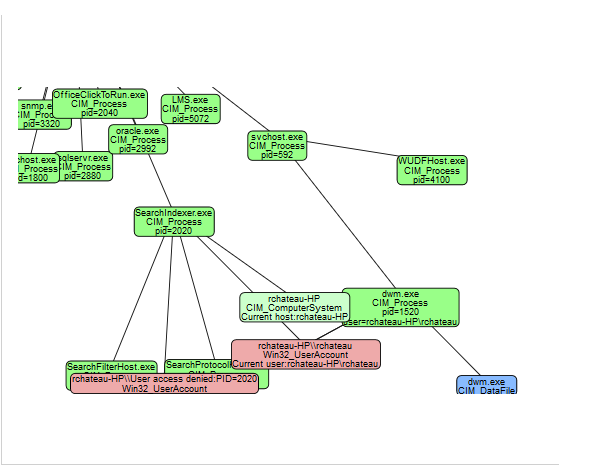
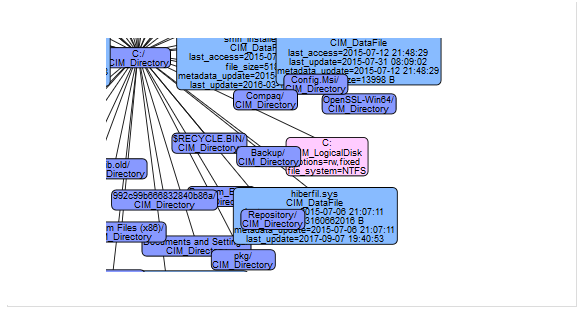
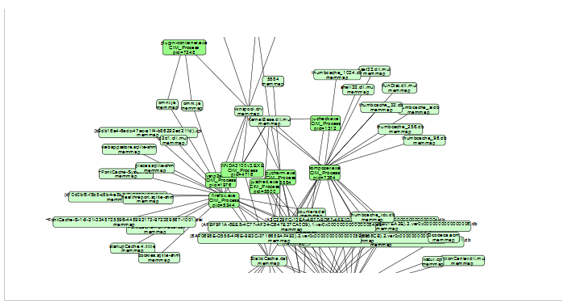
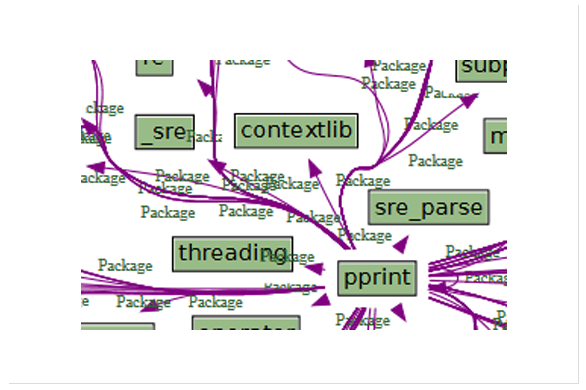
Survol allows to display any software entity
or resources running on a computer. Simply said, it is a
library of Python scripts, each of them displaying a facet of
an information system.
These scripts are run by Survol agents, these
agents running on one or several machines of the user
application network. The web interface then displays and
aggregates the heterogeneous information coming from the
agents. It is not necessary to have an agent on all machines
because many scripts can get information from different
machines than their own. Strictly said, it is possible to run
without an agent at all, just with a static JavaScript page
which connects to the target machines. The agents are very
lightweight and can also run on an Internet of Things (IoT) network.
The data model of Survol is based on classes,
each of them defining a type of computer resources: processes,
machines, files etc... Heterogeneous data are modeled into a
single framework, then aggregated with an RDF inference
engine, creating a global vision of the business information
processing. It can display for example the tree of processes
and sub-processes ...